Memorize, Associate and Match: Embedding Enhancement via Fine-Grained Alignment for Image-Text Retrieval,
Abstract
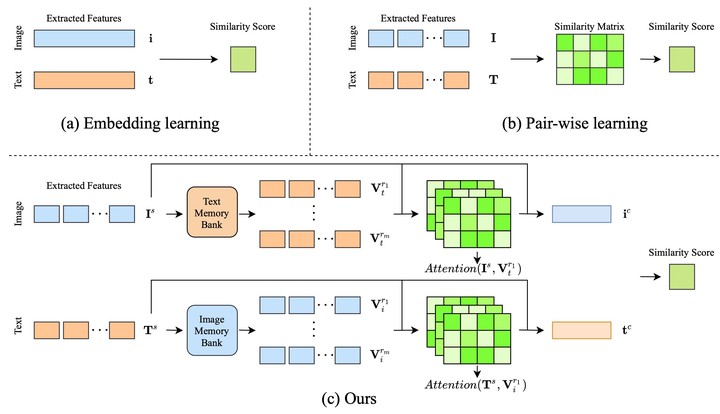
Image-text retrieval aims to capture the semantic correlation between images and texts. Existing image-text retrieval methods can be roughly categorized into embedding learning paradigm and pair-wise learning paradigm. The former paradigm fails to capture the fine-grained correspondence between images and texts. The latter paradigm achieves fine-grained alignment between regions and words, but the high cost of pair-wise computation leads to slow retrieval speed. In this paper, we propose a novel method named MEMBER by using Memory-based EMBedding Enhancement for image-text Retrieval (MEMBER), which introduces global memory banks to enable fine-grained alignment and fusion in embedding learning paradigm. Specifically, we enrich image (resp., text) features with relevant text (resp., image) features stored in the text (resp., image) memory bank. In this way, our model not only accom- plishes mutual embedding enhancement across two modalities, but also maintains the retrieval efficiency. Extensive experiments demonstrate that our MEMBER remarkably outperforms state- of-the-art approaches on two large-scale benchmark datasets.